Kubernetes cluster migration(kubectl篇)
Nov 6, 2023LearningKubernetes
因為EOL的緣故要更新k8s的vm OS,順便將已經很久沒有更新的weave-net換成calico,因此決定重新建一個cluster,再把原本的workload轉移到新的cluster上。
乍聽之下沒什麼問題,畢竟原本就是用manifest管理的,平時更新workload也都是重新將manifest deploy一遍就行。
但真正的問題在於,其中一些workload,像是jenkins,是將app的資料儲存在pv裡,若要轉移到新的cluster上,也要連帶著將pv裡的資料也轉移過去才行。
因此如何轉移pv變成了這次migration最大的課題。
首先梳理一下cluster的狀況:
- 以jenkins為例: deployment -> (經由nfs provisioner創建) pvc -> pv -> nfs
- 作為storage的nfs沒有改變
- 也就是說在nfs上舊cluster用來儲存資料的path不會移動或改變,只是怎麼讓新cluster使用這個路徑作為pv的問題
移植pv與pvc的方法是參考這篇文章實作的:
https://acv.engineering/posts/migrating-a-kubernetes-pvc/
[新cluster] Deploy NFS provisioner
什麼是NFS provisioner呢?這是一個由kubernetes-sigs提供的工具,全稱是Kubernetes NFS Subdir External Provisioner。
可以非常方便的使用既有的NFS server作為pv的儲存路徑,而pv名稱會以${namespace}-${pvcName}-${pvName}的格式呈現。
由於舊cluster上的pv都是透過nfs provisioner去創建的,因此在轉移之前,必須先在新的cluster上也deploy NFS provisioner。
# kubectl apply -k jenkins-nfs-provisioner/test/
storageclass.storage.k8s.io/jenkins-nas-nfs created
serviceaccount/jenkins-nfs-client-provisioner created
role.rbac.authorization.k8s.io/jenkins-leader-locking-nfs-client-provisioner created
clusterrole.rbac.authorization.k8s.io/jenkins-nfs-client-provisioner-runner created
rolebinding.rbac.authorization.k8s.io/jenkins-leader-locking-nfs-client-provisioner created
clusterrolebinding.rbac.authorization.k8s.io/jenkins-nfs-client-provisioner created
deployment.apps/jenkins-nfs-client-provisioner created
# kubectl get all | grep nfs
pod/jenkins-nfs-client-provisioner-69978cf7f4-vzs2g 1/1 Running 0 118s
deployment.apps/jenkins-nfs-client-provisioner 1/1 1 1 118s
replicaset.apps/jenkins-nfs-client-provisioner-69978cf7f4 1 1 1 118s
[舊cluster]將deployment replica=0
接下來要在舊cluster將原本的deployment停止。
在replica=0之後,pod就會被刪除,也因此在新cluster deploy之前會有一段短暫的downtime,不過這次的轉移內容主要是內部使用,些許downtime是可以接受的。再加上部分workload擁有load balancer ip,為了避免ip batting,因此選擇事先將舊cluster上的deployment停止。
# kubectl scale deployment -n test-dev jenkins-deployment --replicas=0
deployment.apps/jenkins-deployment scaled
[舊cluster]取得pv,pvc的yaml
為了在新cluster上可以完全還原pv與pvc(意味著在新cluster上使用與舊cluster相同的pv, pvc名稱,包含hash),必須先取得舊cluster的pv及pvc設定。
kubectl get pv
kubectl get pv <name> -o yaml > pv.yaml
kubectl get pvc <name> -n <namespace> -o yaml > pvc.yaml
[新cluster] Deploy workload到新cluster
因為此時舊cluster的service都已經停止,因此不需要擔心ip batting等問題了。
# kubectl apply -k kustomize/test-dev/
serviceaccount/jenkins-slave created
serviceaccount/jenkins-svc-account created
role.rbac.authorization.k8s.io/jenkins-role created
rolebinding.rbac.authorization.k8s.io/jenkins-role-binding created
configmap/jenkins-jenkins.yaml-mkbm2bt9dm created
configmap/jenkins-master-dtfkmdc465 created
configmap/jenkins-plugins.txt-b72454kth8 created
configmap/jenkins-proxy-b7mkcbg2d9 created
configmap/namespace.conf-gg6m254cct created
secret/jenkins-read-registry-49t6f22mtf created
secret/jenkins-secret created
service/jenkins-service created
limitrange/limit-range created
persistentvolumeclaim/jenkins-pvc created
deployment.apps/jenkins-deployment created
# kubectl get all -n test-dev
NAME READY STATUS RESTARTS AGE
pod/jenkins-deployment-665885c548-4ffh6 1/1 Running 0 108s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/jenkins-service LoadBalancer 192.1xx.xx.xxx 172.xx.xx.xx 80:31394/TCP,50000:31500/TCP 108s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/jenkins-deployment 1/1 1 1 108s
NAME DESIRED CURRENT READY AGE
replicaset.apps/jenkins-deployment-665885c548 1 1 1 108s
此時進入新cluster上的jenkins service的話,可以發現毫不意外的是一個全新的、空蕩蕩什麼也沒有的jenkins。
在NFS上也可以看到provisioner自動創建了一個新的pv的path供新cluster使用。
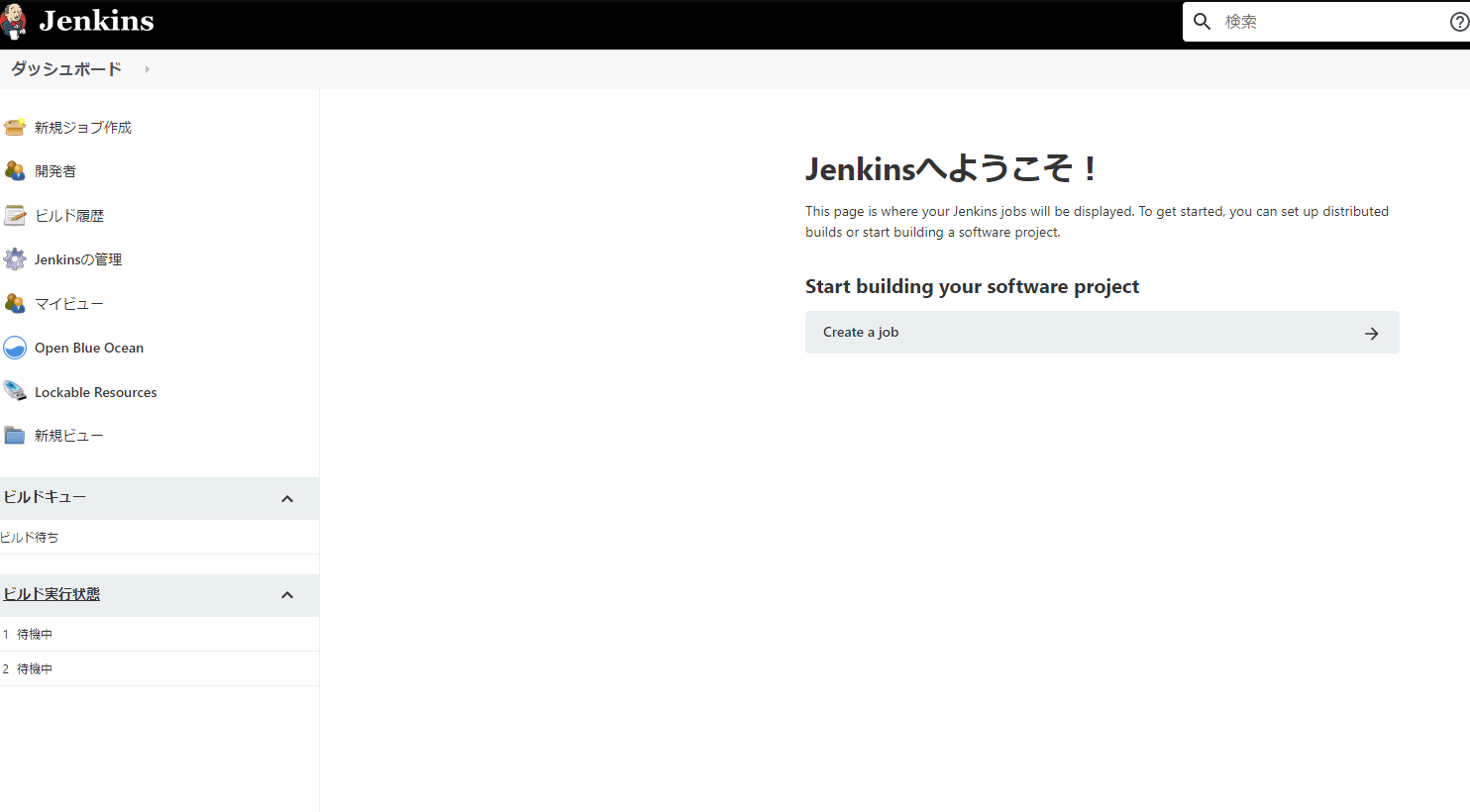
接下來就是如何讓新cluster的jenkins能夠使用舊cluster的pv path了。
[新cluster]將新創建的pv,pvc刪除
第一步就是將新cluster上的deployment停止。
# kubectl scale deployment -n test-dev jenkins-deployment --replicas=0
deployment.apps/jenkins-deployment scaled
最終目的是在新cluster使用舊pv與pvc,因此需要將空蕩蕩的新pv與pvc刪除
# kubectl delete pvc -n test-dev jenkins-pvc
persistentvolumeclaim "jenkins-pvc" deleted
[新cluster]將舊cluster的pv,pvc deploy到新cluster
接下來就是偷天換日(?的時刻了。
總之先將從舊cluster取得的pvc原封不動的apply到新cluster。
# kubectl apply -f pvc.yaml
persistentvolumeclaim/jenkins-pvc created
這時候如果確認pvc的狀態,會發現雖然deploy成功了,但因為yaml中的pv在此刻還不存在(還沒deploy),因此pvc的status顯示Lost。
# kubectl get pvc -n test-dev
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
jenkins-pvc Lost pvc-624f540a-59f5-47a0-8b40-3e5bac1b1c89 0 jenkins-nas-nfs 73s
每個resource在deploy時,都會被label一個metadata uid,這並不是寫在yaml裡的設定,而是在每一次的deploy時動態取得的。
為了等一下能夠讓pv正確認識這個pvc,這裡還需要一個小動作,也就是取得這個新deploy的pvc的uid。
# kubectl get pvc -n test-dev jenkins-pvc -o jsonpath='{.metadata.uid}'
0b25bf00-e7d0-4d7b-b1c7-18a96f9891e6
接下來便是deploy舊cluster的pv。
yaml中有一項設定claimRef是用來判別是哪一個pvc claim了這個pv,將上一步取得的uid patch上去後pv和pvc就藉由這個uid連接起來了。
# kubectl apply -f pv.yaml
persistentvolume/pvc-624f540a-59f5-47a0-8b40-3e5bac1b1c89 created
# kubectl patch pv pvc-624f540a-59f5-47a0-8b40-3e5bac1b1c89 -p '{"spec":{"claimRef":{"uid":"0b25
bf00-e7d0-4d7b-b1c7-18a96f9891e6"}}}'
persistentvolume/pvc-624f540a-59f5-47a0-8b40-3e5bac1b1c89 patched
這時再一次確認pvc的狀態,可以發現不僅狀態已經變成Bound,CAPACITY和ACCESS MODE都正確顯示了。
# kubectl get pvc -n test-dev
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
jenkins-pvc Bound pvc-624f540a-59f5-47a0-8b40-3e5bac1b1c89 5Gi RWX jenkins-nas-nfs 6m47s
[新cluster]將deployment重新回復到replica=1
萬事俱備,只欠東風了!
此時已經成功將舊cluster上的pv,pvc都移植到了新cluster,也確認了狀態沒有問題。
最後一步就是將一開始停止的deployment再度恢復到replica=1,這樣pod會被重新create,若有service也能夠恢復連接。
# kubectl scale deployment -n test-dev jenkins-deployment --replicas=1
deployment.apps/jenkins-deployment scaled
# kubectl get all -n test-dev
NAME READY STATUS RESTARTS AGE
pod/jenkins-deployment-665885c548-v8w7g 1/1 Running 0 11m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/jenkins-service LoadBalancer 192.172.xx.xxx 172.xx.xx.xx 80:31394/TCP,50000:31500/TCP 31m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/jenkins-deployment 1/1 1 1 31m
NAME DESIRED CURRENT READY AGE
replicaset.apps/jenkins-deployment-665885c548 1 1 1 31m
此時再進入jenkins的畫面,應該就能看到原本在舊cluster上創建的內容都出現在新cluster上了!